如何把csdn上面的文章拉取到本地
2023-08-13 11:50AM
可以写一个运行脚本
1. 在Gemfile文件中增加
gem 'httparty'
gem 'nokogiri'
然后运行bundle install
2. 先拉取url
1)在浏览器打开自己的csdn,然后点击F12
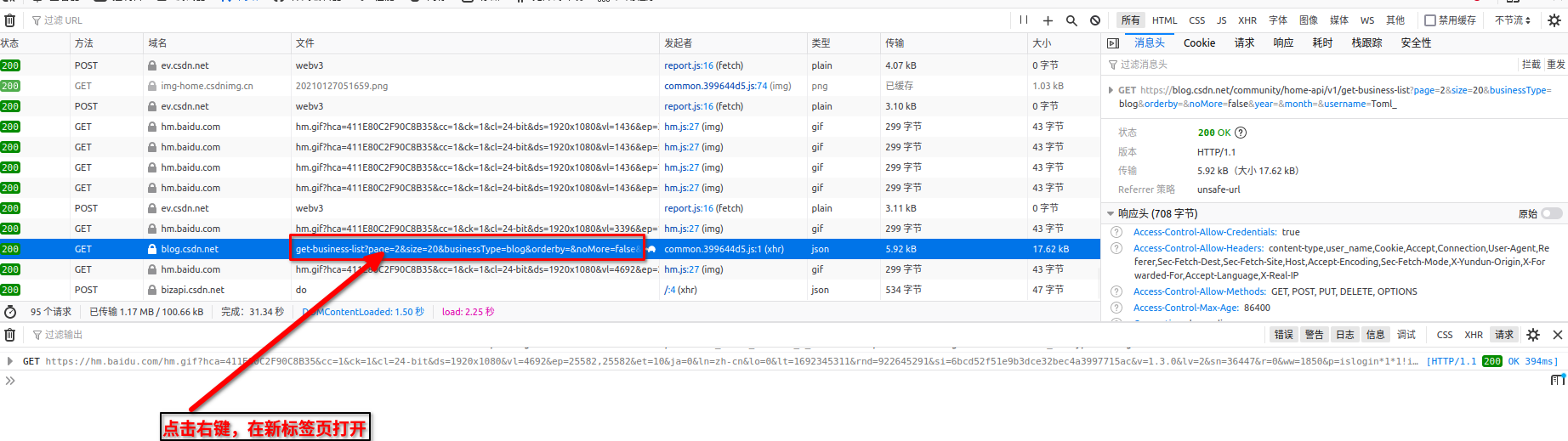
2) 创建 scripts/get_all_post_urls.rb文件
然后把下面代码中的url替换为你复制的链接,然后把复制链接中的 page=1 替换为page#{page}
脚本为:
ENV['RAILS_ENV'] = ARGV.first || ENV['RAILS_ENV'] || 'production'
require File.expand_path(File.dirname(__FILE__) + '/../config/environment')
require 'rails'
require 'rubygems'
require 'json'
def get_single_page_urls page
puts "=== in page: #{page}"
url = ""
response = HTTParty.get(url)
#puts response.body, response.code, response.message, response.headers.inspect
my_body = JSON.parse response.body
puts my_body['data']['list'][0]['url']
my_body['data']['list'].each do |element|
puts element['url']
end
end
(1..12).each do |page|
get_single_page_urls page
end
3). 运行它 bundle exec ruby scripts/get_all_post_urls.rb
3. 拉取文章的标题,内容,时间
1)创建 scripts/get_all_post_body_and_save_to_database.rb文件
脚本为:
ENV['RAILS_ENV'] = ARGV.first || ENV['RAILS_ENV'] || 'production'
require File.expand_path(File.dirname(__FILE__) + '/../config/environment')
require 'rails'
require 'rubygems'
require 'json'
urls = %w{
……把第三步运行的结果复制在这里(记得删除'=== in page: #{page}'打印出来的东,它只是方便你查看url是否拉取完整)……
}
def get_post_body(url)
request = HTTParty.get(url)
parsed_body = Nokogiri::HTML(request.body)
title = parsed_body.css('#articleContentId').first.content
puts "== title: #{title}"
created_at = parsed_body.css('.time').first.content.gsub('已于', '').gsub('修改', '').strip
puts "== 时间: #{created_at}"
article_body = parsed_body.css('#content_views')
puts "== 内容: #{article_body}"
# 检查数据库中是否已存在具有相同标题的文章
if Article.exists?(title: title)
puts "文章已存在,跳过保存"
else
# 这一行的内容替换为你真实文章表的列(我文章列的标题,内容,时间分别是title, content, created_at)
Article.create!(title: title, content: article_body, created_at: created_at)
puts "保存文章成功"
end
end
urls.each do |url|
get_post_body(url)
end
2)运行 bundle exec ruby scripts/get_all_post_body_and_save_to_database.rb
做完上面几步文章就拉取到本地了,但是只拉取了文章的标题,内容,时间,并没有拉取文章的图片,所以本地的文章并不显示文章的图片。
登录
请登录后再发表评论。
评论列表:
目前还没有人发表评论